ID: 46dfdbc7-24f6-4edc-9e61-dab01aa185a1
ROAM_REFS: https://jethrokuan.github.io/org-roam-guide/
Introduction
最先接触到 Zettlekasten (German: “slip box”, plural zettlekästen) 是从 @Tisoga 的推文中得知,如获至宝。在这之前用过 MWeb(内测用户)、iA Writer、Bear、Notion、Obsidian(当时还不知道 Backlinks),都觉得不太合适,尤其是第一步文件夹的分类就让我头疼,很多内容是互相交叉的,并不是简单的可以归在一个分类下面,若是细分的分类过多,又会过于混乱,最后的结果就是“垃圾场”。
- 根据 Zettlekasten 衍生出来的各种 APP 中的 Backlinks 将笔记串联起来,作为一个草稿箱,定期去整理回顾形成自己的知识。
另外一个极为吸引我的就是 Daily Notes 或者 Journals,非常适合我当前的工作场景。「生产问题」或者「零碎的需求」会不断从打断我的工作,有时候会非常紧急需要优先处理「需求」或者「生产问题」,解决后会有两种情况。
-
问题或需求解决后,要花一些时间梳理之前在做的事情才能够重新接续之前的思路继续工作。
-
问题解决后几个月遇到相同或类似的问题,虽然记得解决过,但是当时解决的思路以及细节需要注意的地方就模糊不清了。通常为了万无一失需要重复上次的工作,仔细查看过代码结合业务后,才能作出正确的判断,确保干净利落地解决问题。
上面两种情况完全可以用 Journals 记录解决问题前的工作思路,记录解决问题后的思路,来避免上述两种情况发生。
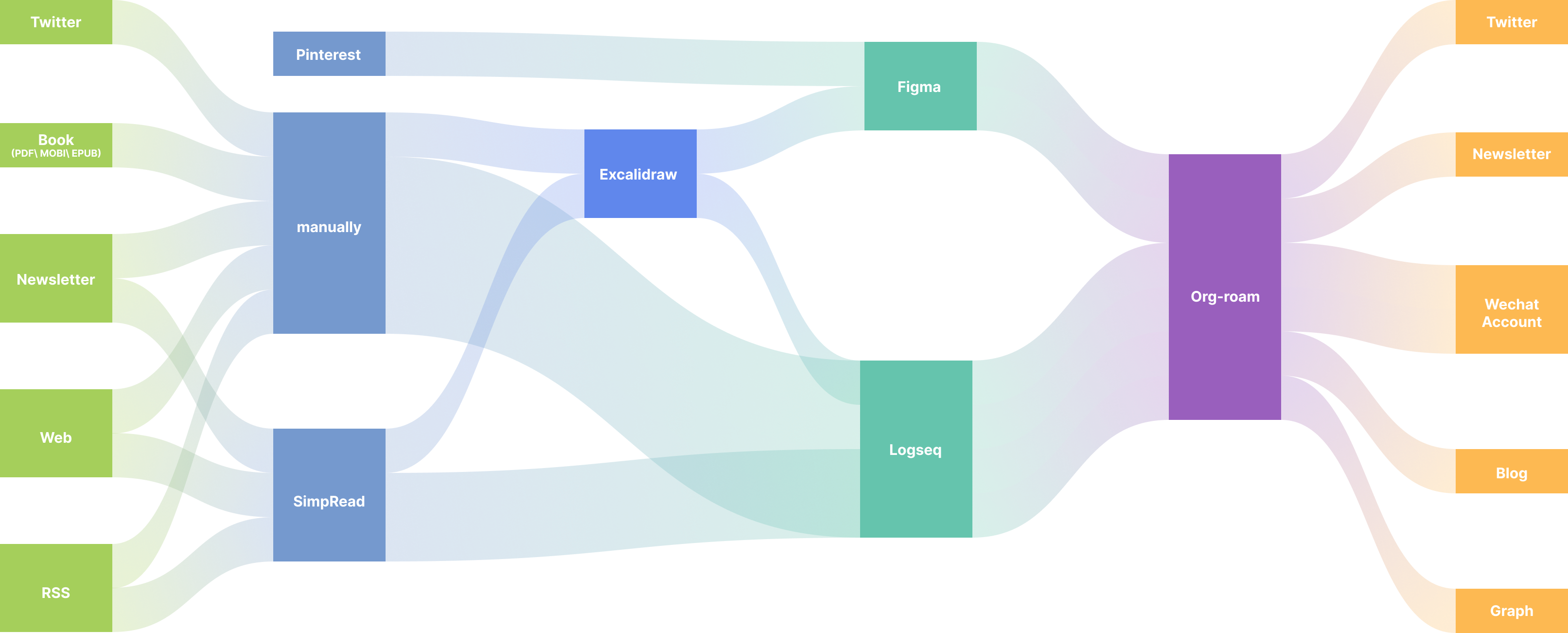
Figure 1: take-notes-sankey
信息大爆炸的副作用就是信噪比降低,通过分阶段的信息处理,不断地归纳、处理形成自己的想法,并将其固化下来,作为知识库。
流程设计
-
图中的流程其实就是多层的过滤器。
从最初的信息源处到 Logseq 的过程,只需要考虑这个信息源是否值得读,是否值得扩展,答案确定则大胆地记入 Logseq。其中零散的思绪及文章阅读记录在 Journals 中,书籍这类大部头则在 page 中记录,前者因为零散在 Journals 中,需要加 page 的双链或 Tag。
Logseq 中 Journals 中的事件重要的会被我移到 Org-roam 中的 Journals.org 文件中,这个文件类似于日记的作用,并不是每天都会记录,记录多了之后按照年份进行分割。
从 Logseq 到 Org-roam 则是知识固化的过程,需要考虑该知识是否以后会被自己再次用到,是否值得扩展,答案确定则精炼后记入,并标明灵感来源,引用材料。因此,Logseq 中记录的都只能算是草稿,需要再次的整合,提高信噪比。
-
对信息源处理时,可以用 Excalidraw 进行流程图、思维图等图的草稿绘制。后续有时间的时候再用 Figma 重新绘制,视觉和逻辑上的重新设计,使得阐述的内容更加直观。
对于产品来说,通过设计降低理解门槛和使用门槛,是一件挺重要的事情。输出文章同样如此。
-
Org-roam 中也有收集想法的地方,Inbox.org,定期会进行清理。 notes 中 outline 结构是由
*实现的,导出时是标题格式,为了随时可以导出发布,要注意 outline 结构。输出是通过 Org-export-dispatch 来转为 .md 或 .html 文件,为了更符合使用的格式,在 Emacs 中做了一些设置。 -
Org-roam-ui 非常优秀,不管是 UI 还是操作性,可以明晰的查看笔记之间的关联,知识是否形成闭环,哪些知识还需要进行拓展阅读。
准则
-
卡片应该具有原子性。这点和编程的原则很像,一个方法只做一件事,在这里也就是只记录一个主题的内容。
-
卡片内容应该具有独立性。这点和上面并不冲突,设想一下,为了保持每个卡片的纯净,X 和 Y 之间的关系,你可能会用 Z 去链接他们。但回顾的时候,没有 Z,单纯回顾 X 或 Y 无法得知两者之间的关联。所以这里不管在 X 或者 Y 中去描述与对方的关系都是可以的,一点点内容的冗余可以使得内容更加独立。
-
遵守奥卡姆剃刀原则。对新工具充分调研,是否满足自己的需求后再考虑替换或增加到现有工作流当中。
-
Literature Notes 需要及时回顾,在一两天内转化为 Permanent Notes 或者直接删掉。
误区
-
All-In-One 的思想。Markdown 的扩展语法实现并不统一,扩展语法的内容导出时经常要手动兼容,或不可再用。云端服务的不可持续性,互联网这么多年已经太多的云端服务用着用着就停掉了。
-
Permanent Notes 并不是不需要回顾和修改了。
-
记太多的内容。从资料中复制大量的原文。笔记应该是对所读内容的提炼:用自己的话改写观点和概念有助于加强理解。
-
太复杂的笔记流程。复杂的工作流通常需要自动化,但自动化不利于笔记的整理,形成最重笔记时应该慎重考虑哪些是需要保留的,否则知识库就会变成垃圾场。
\begin{document} \begin{algorithm} \caption{Vector clocks algorithm} \While{initialisation at node $Ni$} {T := \langle0, 0, …, 0\rangle$ \tcp{local variable at node $N_{i}$}} \While{any event occurring at node $N_{i}$} {$T[i] = T[i] + 1$} \While{request to send message $m$ at node $N_{i}$} {$T[i] := T[i] + 1$\; send $(T, m)$ via network} \While{receiving $(T’, m)$ at node $N_{i}$ via the network} {$T[j] := \max(T[j], T’[j])$ for every $j \in {1, …, n}$\; $T[i] := T[i] + 1$\; deliver $m$ to the application} \end{algorithm} \end{document}