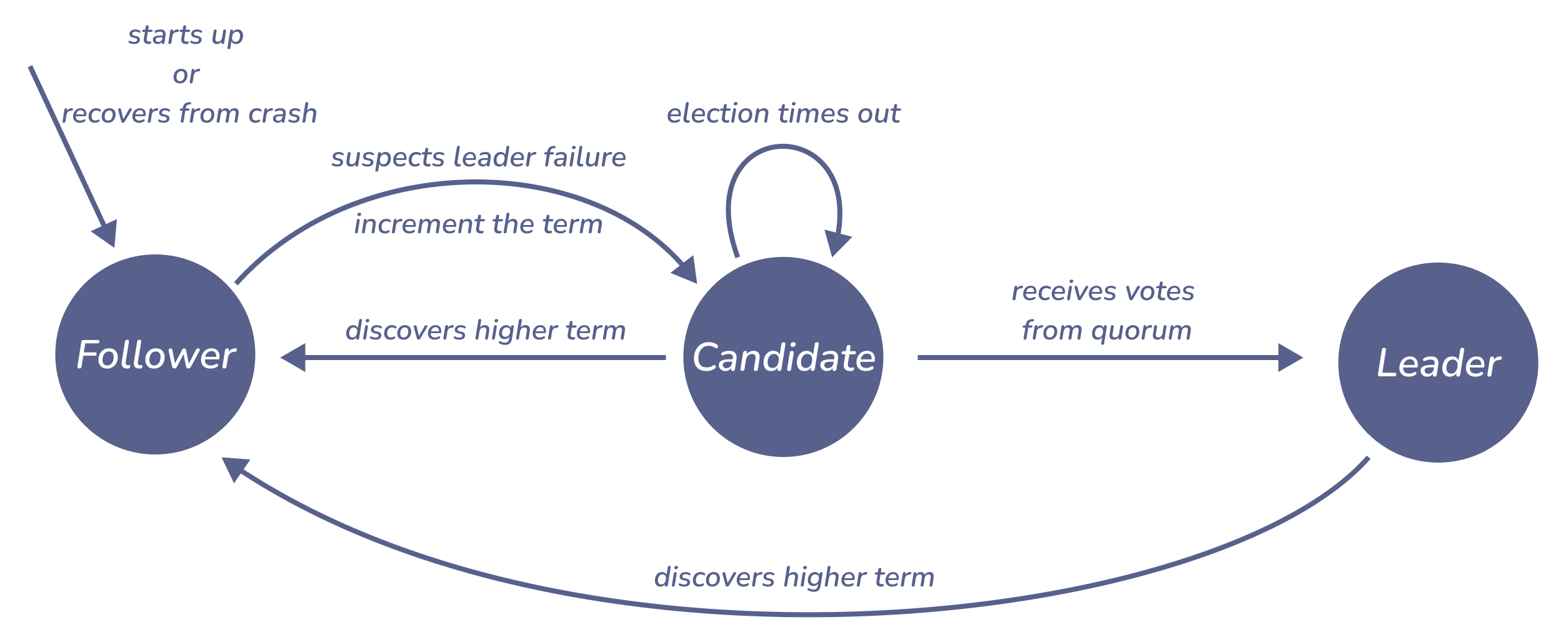
Figure 1: node-state-transitions-in-raft
一个节点有三种状态:leader,candidate 和 follower。当一个节点第一次运行,或者崩溃后恢复时,处于 follower 的状态并且等待其他节点。如果一定时间内没有从 leader 或者 candidate 处收到消息,follower 会怀疑 leader 已经不可用了,并试图成为新的 leader。检测 leader 不可用是随机的,这样可以减少几个节点同时成为 candidate 争取票数成为 leader 的可能。
当一个节点怀疑 leader 不可用时,会转变自身状态为 candidate,递增 term,并在这个 term 中去争取其他节点的票数进行选举。在选举过程中,如果收到其他 candidate 或 leader 发出更高的 term,则会回归到 follower 的状态。如果从 quorum 数量的节点收到票数并选举成功,就会从 candidate 的状态变为 leader 状态。如果在一定时间内没有收到足够的票数,选举会过期,然后 candidate 递增 term 并开始新一轮选举。
一个节点除非崩溃、关闭或者收到其他 leader 或 candidate 处发来的更高的 term,否则会始终处在 leader 状态。当 leader 因为网络原因使得它无法与其他节点沟通时,其他节点就会进行选举,选举出新的 leader,这个时候更高的 term 就产生了。当收到更高的 term 时,之前的 leader 就会变为 follower 的状态。
Initialisation

根据上面的伪代码,在初始化块中定义的变量构成了一个节点的状态。四个变量(currentTerm, votedFor, log, and commitLength)需要维护稳定的存储内(比如硬盘),来保证崩溃的时候状态不能丢失。其他变量在崩溃后恢复时会重置,所以可以存在内存当中。系统中有一个全局变量 nodes,并且每个节点都有一个唯一的 ID。(这边讲的算法没有包含 reconfiguration,也就是从系统中添加或移除节点。)
log 是一个数组,每个条目有属性 msg 和 term。属性 msg 里面就是我们需要通过 total order broadcast 传递的消息,属性 term 包含了被广播的 term 编号。log 数组是以 0 作为下标开始,log 是以尾部 append 新的条目来增长的,Raft 算法在各节点复制 log。当一个日志条目(以及之前的条目)被复制到 quorum 数量节点时,就提交事务。当 log 条目(以及之前的条目)被提交时,就会把条目中的 msg 传递给 Application。在一个 log 条目被提交之前,它还可能发生变化,但 Raft 保证,一旦一个 log 条目被提交后它就是确定了,所有节点将提交相同的日志条目序列。因此,从已提交的 log 条目中按其 log 顺序传递消息,我们就实现了 FIFO-total order broadcast。
当一个节点怀疑 leader 不可用时,增加 currentTerm,将自己的角色设置为 candidate,并通过将 votedFor 和 votesReceived 设置为自己的节点 ID 来为自己投票。然后,它向其他每个节点发送一个 VoteRequest 消息,要求它们投票决定 candidate 是否可以成为新 leader。该消息包含 candidate 的 nodeId、它的 currentTerm(增量后)、它的日志中的条目数,以及它最新一条日志条目。
Voting on a new leader

如果 candidate 的 term 是大于接收者的 term 时,接收者就会变为 follower(即便它在小的 term 里面是 leader)。然后,接收者会检查 candidate 的 log 至少和自己的 log 一样或者更新,防止 log 过期的 candidate 成为 leader,导致 log 丢失。candidate 的 log 最新条目的 term 要大于接收者 log 最新条目的 term;或者 term 相同,candidate 的 log 长度大于等于接收者的 log 长度。那么 candidate 的 log 就是可以接受的。在上面伪代码中的 logOk 可以看到这样的逻辑。
votedFor 变量记录了当前节点在 currentTerm 中给谁投了票,如果 currentTerm 就是 candidate 的 term,candidate 的 log 是最新的(也就是 logOk 为 true),并且在当前这个 term 中没有给其他节点投过票,那么就将 candidate 的 nodeId 记录在 votedFor 中,并发送包含 true 的 VoteResponse 的消息给 candidate。否则,则发送包含 false 的 VoteResponse。除了成功和失败的标识外,还会附带上当前节点的 ID 以及当前的 term。
Collecting votes

回到 candidate 这边,如果收到的消息中 term 高于 candidate 的 term,则会取消选举并过渡到 follower 状态;如果两者的 term 相等,则 candidate 就会讲投票者的 ID 加入到 votesReceived 集合中。
如果投票构成了 quorum,那么 candidate 会过渡到 leader 状态。作为领导者的第一个动作,就是更新 sendLength 和 ackedLength 变量(解释见下文),然后为每个 follower 调用 ReplicateLog (定义见(Raft (5/9): replicating from leader to followers)函数。这样做的目的是向每个 follower 发送一条消息,告知他们新的 leader 的情况。
sentLength 和 ackedLength 给每个节点 ID 映射了一个整数(非 leader 不需要这些变量)。对于每个 follower F,sentLength[F] 记录了从 log 开始有多少 log 条目发送给了 F;ackedLength[F] 记录了有多少 log 条目已经被 F 确认收到了。在成为 Leader 之前,节点会将 sentLength[F] 初始化为 log 的长度(这里是假设所有的 follower 都已经同步了所有的 log,这里的假设是有问题的,具体解决会在 Raft (8/9): leader receiving log acknowledgements),ackedLength 初始化为 0。
Broadcasting messages

以上伪代码中,当 Application 希望通过 total order broadcast 广播消息时,只需要简单的添加一个新的 log 条目进 log 当中,并更新 ackedLength 为最新 log 的长度,然后对于其他每个节点都调用 ReplicateLog。
leader 在即使没有新消息需要广播时,也会定期为其他每个节点调用 ReplicateLog,这样可以让其他 follower 知道 leader 一直处于可用状态以及让丢失的消息得到重传。
Replicating from leader to followers

ReplicateLog 方法是从 leader 利用 followerId 发送任何新的 log 条目给 follower。prefixLen 是已经发送给 follower 消息的数量,suffix 就是还没有发送给 follower 的消息。所以当 sentLength[follower] = log.length 时,suffix 是一个空数组。
Followers receiving messages

首先,如果消息的 term 比 follower 当前的 term 高,则更新当前的 term,并接受消息的发送者为 leader。相等的时候,也会和之前一样的逻辑,承认发送者为 leader。
prefixLen 为 suffix 包含 log 条目之前的条目数量,follower 要求自己当前的 log 长度要大于等于 prefixLen,并且 prefixLen 长度前的最后一个 log 条目中的 term 要与 leader 的 prefixTerm 相同1。Raft 算法保证两个节点相同下标对应的 log 条目中的 term 相同,那么在这之前的 log 都是相同。
以上条件满足就会调用 AppendEntries 将 suffix 添加到自己的 log 当中。
Updating followers’ logs

follower 利用该函数讲从 leader 那里收到的条目扩充到 log 当中。如果节点本地的 log 长度大于 leader 发来消息中的 prefixLen,那么我们就要检查差异的这部份 log 条目是否与 suffix 中的条目一致。如果不一致,我们则需要舍弃这部份差异,只保留 prefixLen 长度的 log。这种情况发生在前一个 leader 发送的 log 已经被合并到节点本地 log 当中,而同时因为一些原因新的 leader 发送来新的 log。
然后,任何新的 log 都会被追加到 follower 本地的 log 当中,即便是消息重复的情况下,这个操作也是幂等的。follower 检查 leaderCommit 是否大于本地的 commitLength,满足条件则可以将 log 当中的 msg 传递给 application,并对本地 commitLength 更新。
Leader receiving log acknowledgements

这里回到 leader 这边。leader 会检查发送者的 term:如果发送者的 term 大于接收者的 term,那么意味着新 leader 选举已经开始,所以当前的 leader 会变为 follower 的状态。
如果 term 相同,并且详细中的 success 为 true,则更新 sendLength 和 ackedLength,记录 follower 确认过的 log 数量,然后调用 CommitLogEntries 函数。如果 success 为 false,则 follower 没有接收消息,这个时候 leader 会递减 sendLength,并嗲用 ReplicateLog 重新发送 LogRequest 消息2。
Leader committing log entries

被 quorum 确认过的 log 条目就可以被 leader 提交,当 log 条目被提交,消息就被传递给 Application。